before_release commands or Ephemeral SSH Sessions.
📘 Each one of your App’s Services gets a new Release when you deploy, etc. In other words, Releases are Scoped to Services, not Apps. This isn’t very important, but it’ll help you better understand how certain Aptible Metadata variables work.
Lifecycle
Aptible will adopt a deployment strategy on a Service-by-Service basis. The exact deployment strategy Aptible chooses for a given Service depends on whether the Service has any Endpoints associated with it:
📘 In any cases, new Containers are always launched after before_release commands have completed.
Services without Endpoints
Services without Endpoints (also known as Background Services) are deployed with zero overlap: the existing Containers are stopped before new Containers are launched. Alternatively, you can force zero downtime deploys either in the UI in the Service Settings area, aptible-cli services:settings, or via our Terraform Provider. When this is enabled, we rely on Docker Healthchecks to ensure your containers are healthy before cutting over. If you do not wish to use docker healthchecks, you may enable simple healthchecks for your service, which will instead ensure the container can remain up for 30 seconds before cutting over.Docker Healthchecks
Since Docker Healthchecks affect your entire image and not just a single service, you MUST write a healthcheck script similar to the following:
Services with Endpoints
Services with Endpoints (also known as Foreground Services) are deployed with minimal (for TLS Endpoints and TCP Endpoints) or zero downtime (for HTTP(S) Endpoints): new Containers are launched and start accepting traffic before the existing Containers are shut down. Specifically, the process is:- Launch new Containers.
- Wait for the new Containers to pass Health Checks (only for HTTP(S) Endpoints).
- Register the new Containers with the Endpoint’s load balancer. Wait for registration to complete.
- Deregister the old Containers from the Endpoint’s load balancer. Wait for deregistration to complete (in-flight requests are given 15 seconds to complete).
- Shutdown the old Containers.
Concurrent Releases
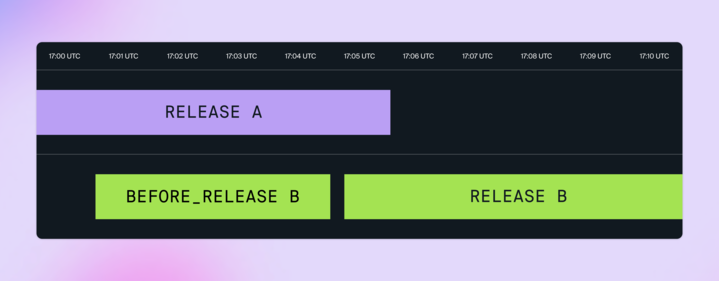
❗️ An important implication of zero-downtime deployments is that you’ll have Containers from two different releases accepting traffic at the same time, so make sure you design your apps accordingly!
For example, if you are running database migrations as part of your deploy, you need to design your migrations so that your existing Containers will be able to continue working with the database structure that results from running migrations.
Often, this means you might need to apply complex migrations in multiple steps.
Graceful Stop of Old Release Containers
When we stop the containers associated with the older release, aSIGTERM is initially sent to the main process within your container. After a certain grace period (by default 10 seconds), a SIGKILL is then sent to terminate the process regardless of if it is still running. You can customize this stop timeout grace period before the SIGKILL is sent by editing the stop timeout associated with the service, either in the UI (in the service Settings tab), in the CLI, or with terraform.
For example, your worker application may want to capture SIGTERM signals and put work back onto a queue before exiting cleanly to ensure jobs in process get picked back up by the new release containers. For services without endpoints that are not configured to use zero downtime deployment, we do wait for all containers to exit before starting up new containers, so for the duration of the time it takes to stop, there would be no containers processing work. Therefore it is recommended to keep this timeout as short as possible, or use zero downtime if possible.
However, note that your operations will wait on the containers to stop, so increasing the timeouts and having containers fail to exit quickly will increase the time taken for deploy, restart, configure, scale, etc. Operations are run sequentially against a given resource, so increasing the time of an operation could delay execution of further operations run against that same application or service.
The maximum time allowed for configurable stop timeout is 15 minutes.